
藍莓因其豐富的營養成分常被譽為超級食物,因此引起了人們對其健康益處和烹飪多樣性的高度關注。在各種藍莓品種中,野生藍莓以其高含量的維生素、錳、花青素、類胡蘿蔔素、鉀、鋅和抗氧化劑而脫穎而出。值得注意的是,與栽培藍莓相比,野生藍莓的抗氧化劑含量顯著更高,使其成為農業市場上一種備受追捧的商品。
為了最大程度地提高野生藍莓的產量,研究人員和種植者都在尋求創新的方法來預測和優化生產成果。其中一種途徑是利用預測建模技術,基於從田間觀察中得出的一系列豐富的預測變量來預測野生藍莓的產量。這些變量涵蓋了影響野生藍莓生長和生產力的各種因素。
Induction #
在這項分析中,我們旨在利用從Kaggle競賽中提供的野生藍莓產量預測數據集中獲取的數據,開發一個用於估算野生藍莓產量的預測模型。我們的分析將集中於整合各種預測變量,包括環境因素、授粉者密度和植物特徵,以建立一個穩健的預測模型。
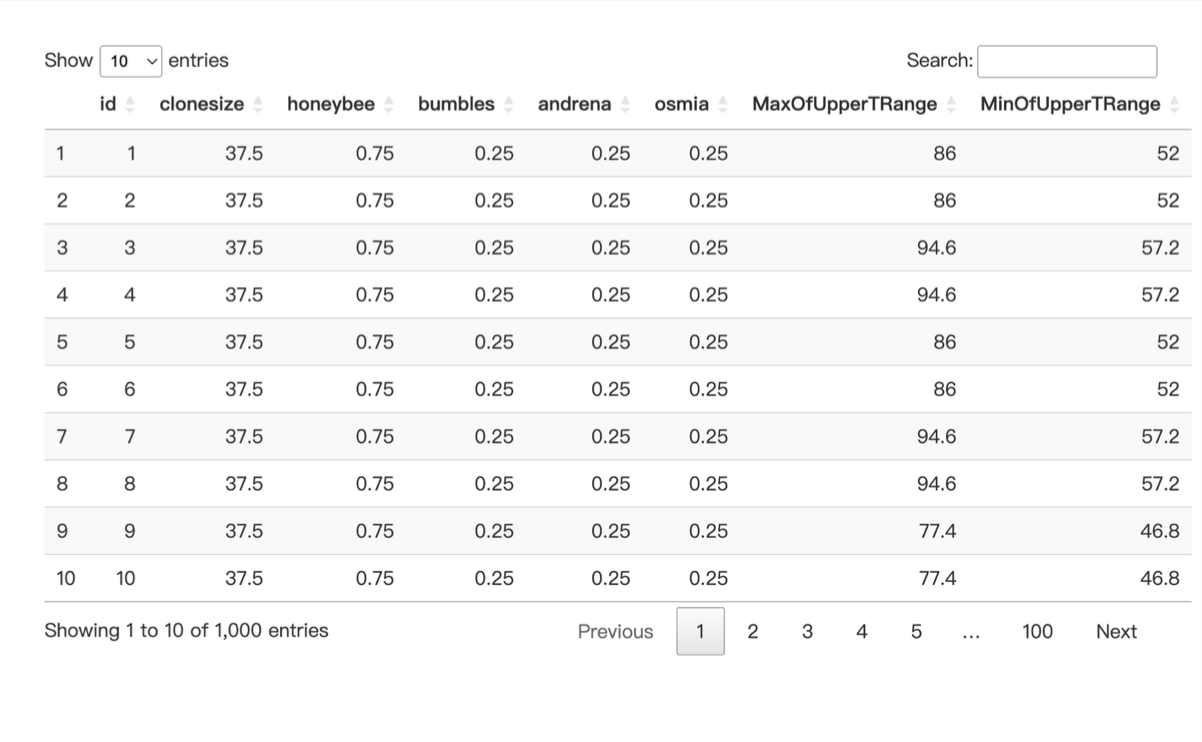
讓我們看看數據集中有哪些變量。
-
Clonesize ( m2 ) : 每平方公尺中有多少比例的藍莓是經由無性生殖所培育出來的。
-
Honeybee ( m2 / min ) : 田間每平方公尺蜜蜂的密度。
-
Bumbles ( m2 / min ) : 田間每平方公尺大黃蜂的密度。
-
Andrena ( m2 / min ) : 田間每平方公尺安德瑞那蜂的密度。
-
Osmia ( m2 / min ) : 田間每平方公尺奧斯米亞蜂的密度。
-
Max.U.T ( Max of Upper TRange ◦F ) : 在整個開花季節期間,每日上限氣溫的最高紀錄。
-
Min.U.T ( Min of Upper TRange ◦F ) : 在整個開花季節期間,每日上限氣溫的最低紀錄。
-
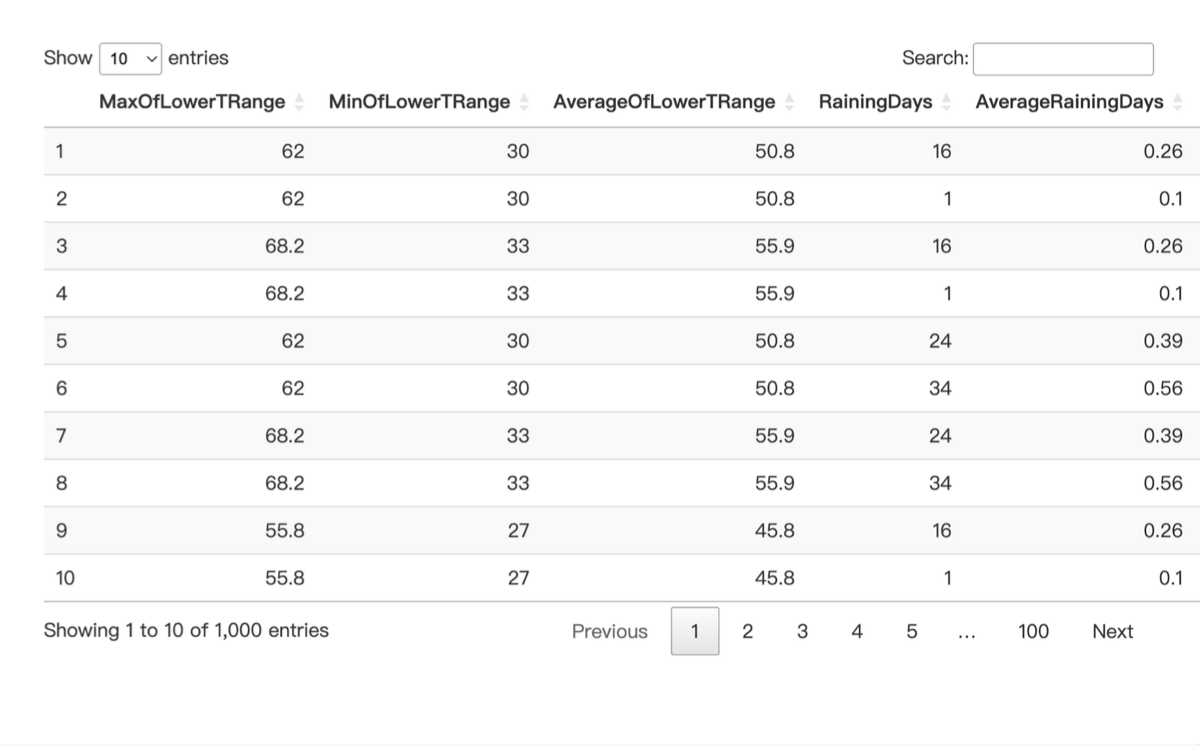
A.U.T ( Average of Upper TRange ◦F ) : 在整個開花季節期間,每日上限氣溫的平均值。
-
Max.L.T ( Max of Lower TRange ◦F ) : 在整個開花季節期間,每日下限氣溫的最高紀錄。
-
Min.L.T ( Min of Lower TRange ◦F ) : 在整個開花季節期間,每日下限氣溫的最低紀錄。
-
A.L.T ( Average of Lower TRange ◦F ) : 在整個開花季節期間,每日下限氣溫的平均值。
-
R.D ( Raining Days) : 在整個開花季節期間,降雨量大於零的總天數。
-
A.R.D ( Average Raining Days) : 在整個開花季節期間,降雨天數的平均值。
-
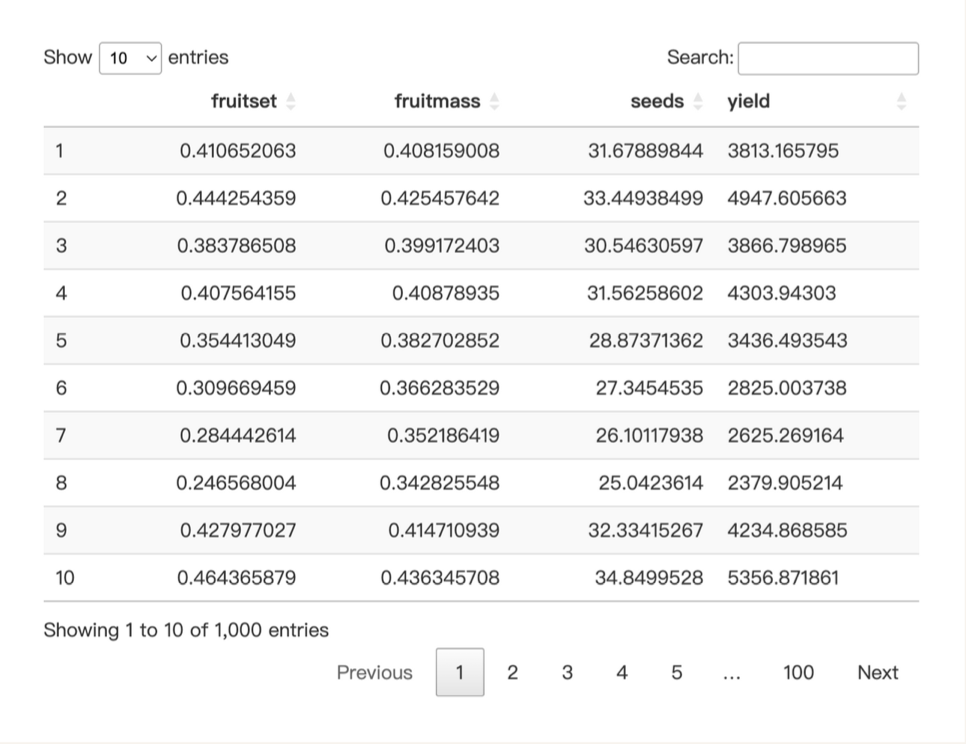
Fruitset : 最終結果形成果實的花朵比例。
-
Fruitmass ( g ) : 單個藍莓果實的平均質量(克)。
-
Seeds : 平均每個藍莓果實中發現的種子總數。
反應變量 : Yield(產量)
{kind=link}
{kind=link}
{kind=link}
Exploratory Data Analysis, EDA #
Correlation #
根據對數據集的初步分析,我們從 Figure 4: Correlation Plot 中,發現右下角的 Fruitset、Fruitmass、Seeds 和 Yield 彼此之間幾乎完全呈現正相關;我們可以預期它們之間密切相關,因為更高的結果比例提升了產量基數,而單個藍莓果實的平均質量更是如此。
{kind=link}
而大黃蜂和奧斯米亞蜂也與 Fruitset、Fruitmass、Seeds 和 Yield 呈正相關,我們推測這可能是因為蜜蜂授粉對藍莓而言是結果的必要因素,因此更高的田間蜜蜂密度可以帶來更好的結果率,進而影響產量。
此外,無性生殖比例大小與Fruit-set、Fruitmass、Seeds、Yield呈負相關。經過了解,我們發現這是因為有性繁殖的後代生產量將高於無性繁殖。
降雨天數也與 Fruitset、Fruitmass、Seeds、Yield 呈負相關;因為雨水會導致花朵凋謝。
野生藍莓 vs 人工種植藍莓 #
經過資料查詢後,我們知道市場上的藍莓可以大致上分為野生藍莓與人工種植的藍莓,而他們之間有什麼不同呢?
通常人工種植的藍莓具有更高的產量,這是因為人工種植的藍莓可以在受控的環境中進行管理,包括土壤、水分、陽光、溫度等因素都可以被精確地調節,從而最大程度地促進藍莓的生長和產量。
此外,人工種植的藍莓往往使用高產量的品種,並且可以利用現代農業技術和機械化設備來提高生產效率,進一步增加產量。相比之下,野生藍莓的產量通常較低,因為它們生長在自然環境中,受到自然條件的限制,例如土壤品質、水分供應、陽光照射等因素都無法被控制。此外,野生藍莓的生長可能受到天敵和自然災害的影響,進一步影響了產量。
我們將降雨天數除以平均降雨天數,大致從 Figure 6: Berry Species 將藍莓生長的天數分為兩種,I型藍莓(生長周期較短)的產量較高,我們猜測可能是人工種植,而II型藍莓(生長周期較長)的產量較低,我們猜測可能是野生藍莓。
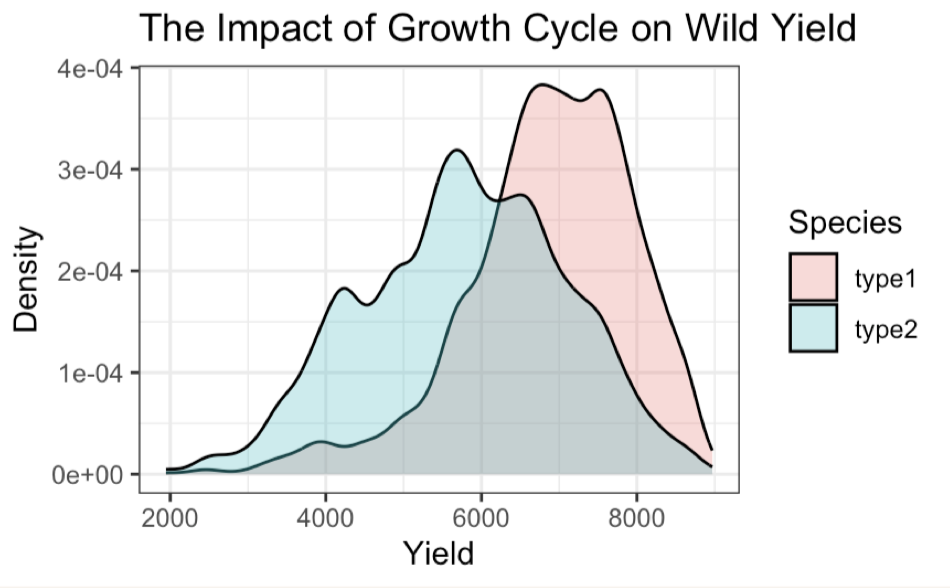{kind=link}
那麼我們是如何區分它們的呢?我們在 Figure 5: Grandma Berry? 中,刪除了一些單個數據,不只是因為他們相較於兩種藍莓的週期而言差距比例甚大,有些數據更是十分的不合理,請試想一下,生長週期是其他藍莓50倍長的藍莓,或許可以稱為「藍莓奶奶」了吧。在我們調整完數據之後,總共還有20,000多條數據。
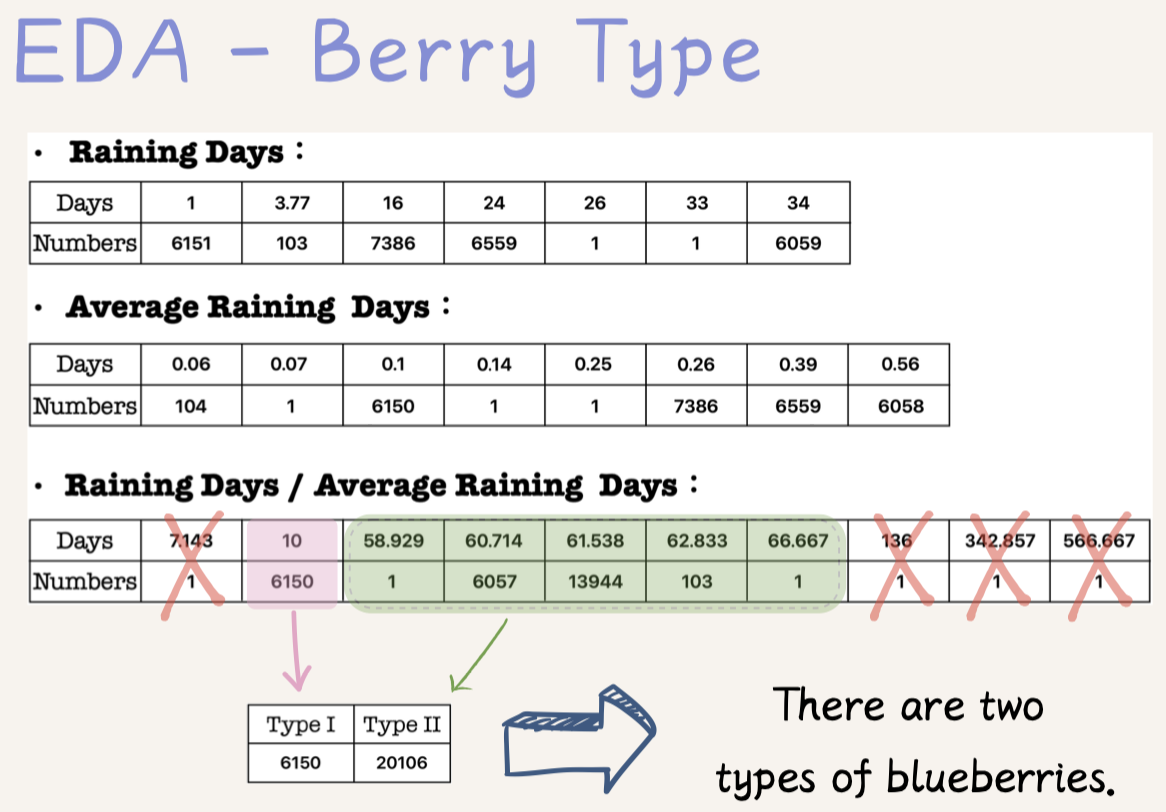{kind=link}
生長環境對藍莓的影響 #
接著我們想透過觀察產區的均溫,來尋找關於生長區域所帶來的特徵。我們將最高上限氣溫和最高下限氣溫相加並取平均值,得到一個新的平均溫度,我們使用新的平均溫度將產區大致分為四個區域,見Figure 7: Four Areas 。
{kind=link}
在繪製了區域和產量比較圖後,由於藍莓實際上也有適合生長的溫度,過高或過低的溫度都會抑制其生長。我們發現儘管第2區和第3區的溫度不是最高的,從 Figure 8: Compare Areas 中可以看出,它們的產量在四個區域中是最好的。
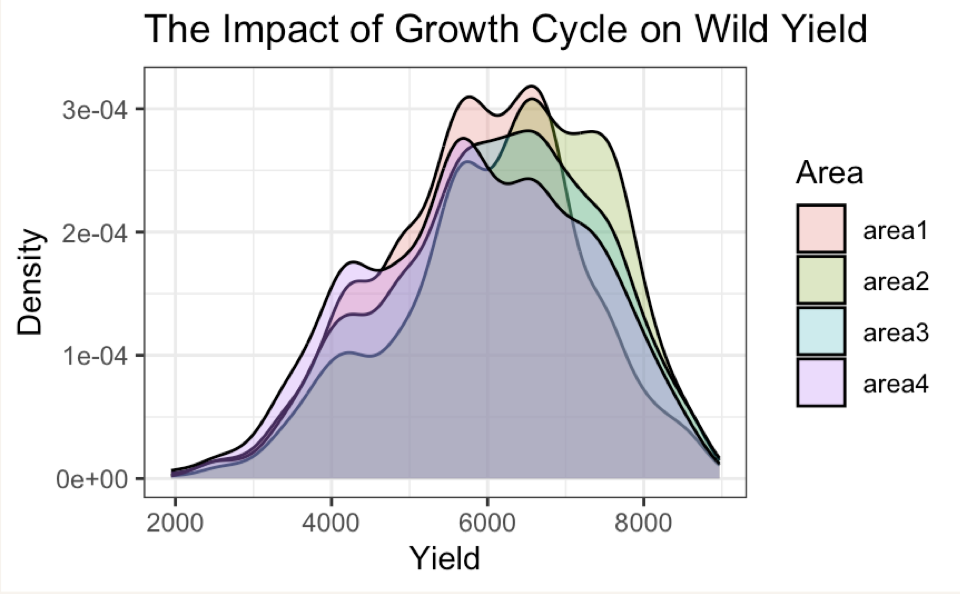{kind=link}
Method #
K-Fold Cross Validation #
在開始模型建構之前,我們使用交叉驗證來確保模型不會過度擬合。我們採用K折交叉驗證的方法,在這裡我們簡單的做一個介紹。
K 折交叉驗證將數據集分成 K 個相似大小的子集,稱為 folds,然後進行K次訓練和測試。在每一次迭代中,將其中一個 fold 作為測試集,其餘的 K-1 個 fold 作為訓練集。而在 K 次迭代完成後,將每次測試的性能評估指標取平均值,作為模型的最終性能評估。
交叉驗證可以提供對模型性能的更穩健的估計,因為它在不同的子集上進行了多次測試和訓練,減少了對單一切分的依賴性,也避免了極端的樣本組合可能對模型 over fitting 的影響。在這裡的模型建構中,我們將 K 設定為 5 。
Compare Models #
我們總共對四種模型進行了個別的調整。本次比賽的參賽人數約 1900 人,而評分標準基於模型的平均誤差(MAE)。最後調整後的線性模型排名約為 1570,隨機森林排名為 1400,XGBoost 排名較低,在 1030 左右,表現最好的是 LightGBM,排名 334。
那麼我們是如何做到的呢,資料清洗、特徵工程與對模型的調整是必要的,接下來我們會對資料的建模與調整做更近一步的介紹。
這是一個被設計好的問題? #
在進入模型介紹之前,透過觀察產量的變數後,我們懷疑它是一個看起來像類別的數值變數。但我們最終將其視為連續變數。因為如果我們將這個問題視為分類問題的話,會有約500個類別,甚至有的類別只有一個樣本,基本上無法將變數視為離散的來進行預測。
而我們也發現了一些資料中的不合理之處,例如變數中的 Honeybees 在標準化之後,我們發現甚至有密度超過46個標準差的蜜蜂,看起來十分可疑。考慮到這個變數與其他變數之間交互作用均對模型幾乎沒有影響,經過思考後我們決定刪除 Honeybees。
但這只是一個開頭,綜合前面在整理資料時發現諸如「藍莓奶奶」之類的問題後,不禁讓我們對數據對數據的紀錄有點懷疑,甚至思考這些是否都是被刻意混入的錯誤資訊。
而 Kaggle 官方的這筆資料是使用小數據產生大數據來訓練,但是如果仔細查看數據,會發現有些數據是相似更甚至是大致相同的,因此在完成模型建構後,我們懷疑測試集也是從訓練集中分離出來的。
Linear Regression #
線性模型可以很好地表達我們在數據中發現的問題。從 Figure 9: Linear Model 中可以看到,資料實際上其實具有離散型變量的特徵,但我們對此並沒有太多辦法。
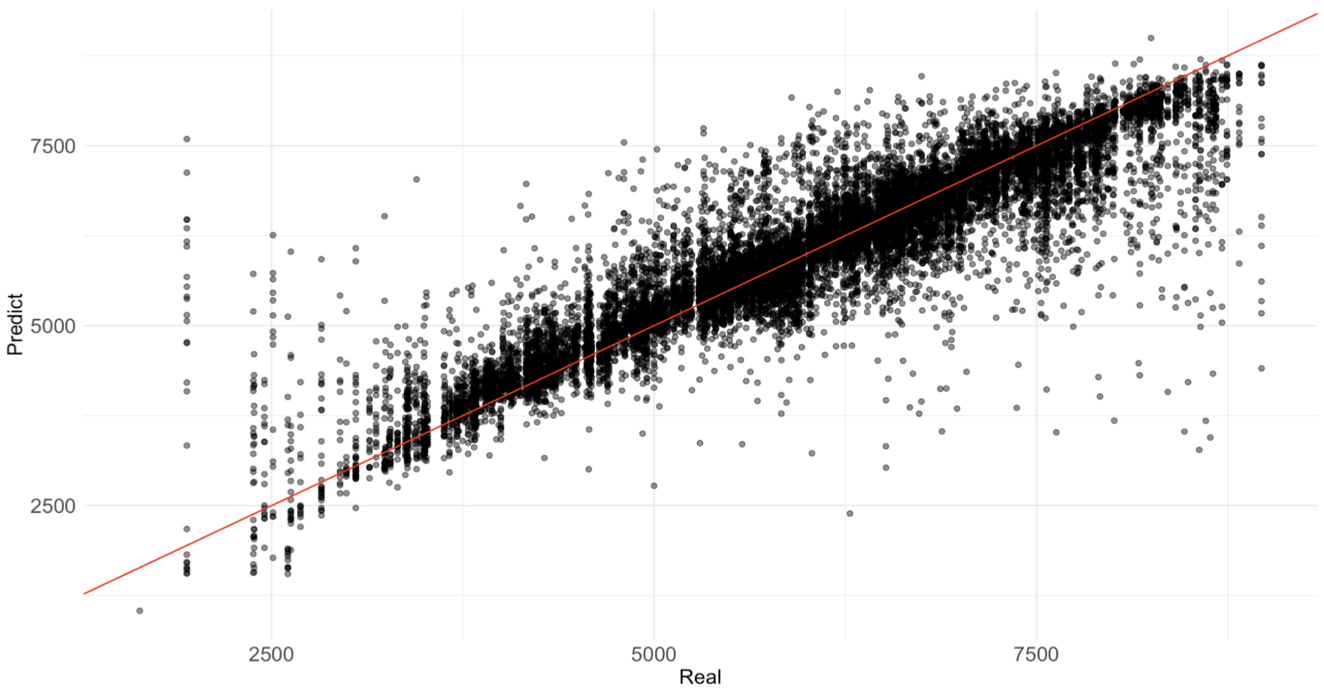{kind=link}
就像在前面所提到,我們觀察出產量是個看起來具有類別特徵的數值變量一樣,模型也可能會獲取這種信息,因此當模型輸出預測結果時,也會傾向於預測類別,但一旦分類不正確,就會導致非常大的錯誤。這個問題在線性模型中特別嚴重,後續模型數據中段的預測性能將比線性模型好很多,但在兩端點仍會有類似問題。我們目前可能無法很好地解決這類問題。
回到比較模型優劣的部分,線性模型在這些數據中的優勢是運行速度快且模型從統計角度高度可解釋,同時可以快速篩選出顯著影響模型的異常資料。缺點是模型的結果受異常值的高度影響,而且依賴於數據的線性關係,導致我們需要將資料清洗過才能有效的做呈現。
由於後續模型的結果的分佈圖與線性模型相似,因此僅展示圖9,不再展示更多結果。
Random Forest #
關於隨機森林模型我們並沒有太多著墨於此,由於調整模型的效果不大,甚至更換種子的隨機性影響都大於模型本身的參數調整。
在這筆資料中,使用它來建模的優點是它是開箱即用的,基本上不需任何的調整表現就比線性模型更佳,我想這可能是資料型態本身較適合 tree base 的模型,由於看似多分類問題的數據型態導致他可能並不是那麼適合以線性的方法來建模,不過他並沒有改善我們在線性模型中所遇到的問題,因此這個模型對我們結果的提升十分有限。
XGBoost #
當我們開始嘗試使用 XGBoost 建模調參時,我們從中發現了一件重要的事,甚至使我們對模型的調整方向有很大的轉變。起初我的想法源於參考原始論文後,樹深不宜太深所以均往其他參數方向做調整,但經過一系列測試後,我們將樹的深度設置為5,如此的深度超出了我的預期。
基於我之前在模型調優方面的經驗,如此深的樹可能會導致過擬合。但在這裡卻能使模型的表現更好,我假設更深的樹所帶來過擬合造成結果恰好會如同我們前面所看到的數據分佈一般,即是具有類別特徵的連續型變數作為結果。
同時這個結果讓我思考了一個問題:訓練集和測試集是否來自相同的底層過程?是否因為這樣的原因而導致我們原以為的過凝合其實是更優的解決方案,即我們認為會產生的過凝合問題在這筆資料中並不存在。無論如何,在這個數據集中,更深的樹深確實提高了預測準確性,並且對資料兩端值時的預測值是四個模型中較好的。
LightGBM #
接著延續我們在 XGBoost 中得到的想法,在 LightGBM 的模型調整中,我們採用了生成更多葉節點、增加迭代次數以及使用較低學習率的策略。最終我們將葉節點數量設置為28。
然而,我們觀察到這些葉節點往往集中在特定的分支上,導致子模型甚至比 XGBoost 中的樹深要更深。這也超出了我對模型的預期。與我們在 XGBoost 中的發現類似,這是否意味著更複雜的樹增強了模型的準確性?進而使 LightGBM 成為我們目前解果最好的單一模型。但 LightGBM 雖然整體精度是四個模型中最高的,但它犧牲了兩端數據預測的準確度。
Conclusion #
經過大量時間和精力的投入,通過特徵工程、調整參數和改進模型擬合度,我們發現研究結果仍然相當出色,且模型的排名表現也十分優異。在這次的分析中我們有三個主要結論。
首先是數據清洗與特徵工程的重要性,在清洗過程中可以挑出異常數據。否則,未經清洗的數據直接投入模型,效果通常不會很好。特徵工程經過用了解藍莓的種類和生產區域後,所生成的特徵對後續分析有很大幫助。
第二是調整參數和選擇模型也非常重要。通過調整不同的參數可以提高模型的適應性,而不同模型的結果也,線性模型解釋力強,但效果不佳;隨機森林和 XGBoost 解釋力不強,但對數據兩端極值的預測值較為合理;LightGBM 雖然整體準確率最高,但犧牲了兩端的數據。如果將這這些模型結合成一個混合模型,排名分數應該會進一步提高。
最後是關於後面模型的參數調整讓我獲益良多,有種讀萬卷書不如行萬里路的感覺,在完成這次資料分析前,我不曾試過這樣進行模型調整效果反而會更好的案例,也對資料樣貌有了更深一層的認知。
後續工作與感想
關於這筆資料,或許可以將更多異常數據提出來,形成一個新的數據集並單獨建模,這應該對提高準確性有很大幫助。也可以嘗試混合模型,但需要對混合模型的架構進行更多嘗試以求獲得更好的解果。總而言之,我們在 Kaggle Playground 競賽中學到了很多,這次分析對我而言是一次很好的嘗試。也謝謝閱讀至此的各位,我會繼續在數據分析上力求精進,以求能做出更好的成果。