欣賞電影與劇集是現代人眾多生活消遣之一,而如何推薦一部令使用者滿意的影集也成為各個應用程式在現代科技發達下的新戰場。我們生活中處處皆充滿了推薦系統的影子,舉凡購物網站、社群媒體、甚至連搜尋引擎均是如此,而我基於對這個領域的好奇心,加上在碩士論文研究上有考慮向推薦系統發展的緣故,這個學期我跨系修習了資工系的推薦系統課程,因此也就衍生出了這份期末報告,由於教授課程規劃的緣故,所有的報告統一均採用 MovieLens 100k 這筆資料,而這次的報告也在課程中拿到最好的成績。
Induction #
這筆資料來自於 grouplens 這個網站,資料中一共有 100,000 條評分,它們分別来自 943 位使用者對 1682 部電影的評價。而本次的資料一共分成三個部分,它們分別有使用者的相關數據、電影的相關數據以及使用者對電影的評分。接著就讓我們來一一介紹我們有使用到的部分。
-
使用者數據:
-
user_id
-
age : 使用者的年齡
-
gender
-
occupation : 使用者的職業
-
-
電影數據:
-
movie_id
-
movie_title
-
release_date : 電影上映日期
-
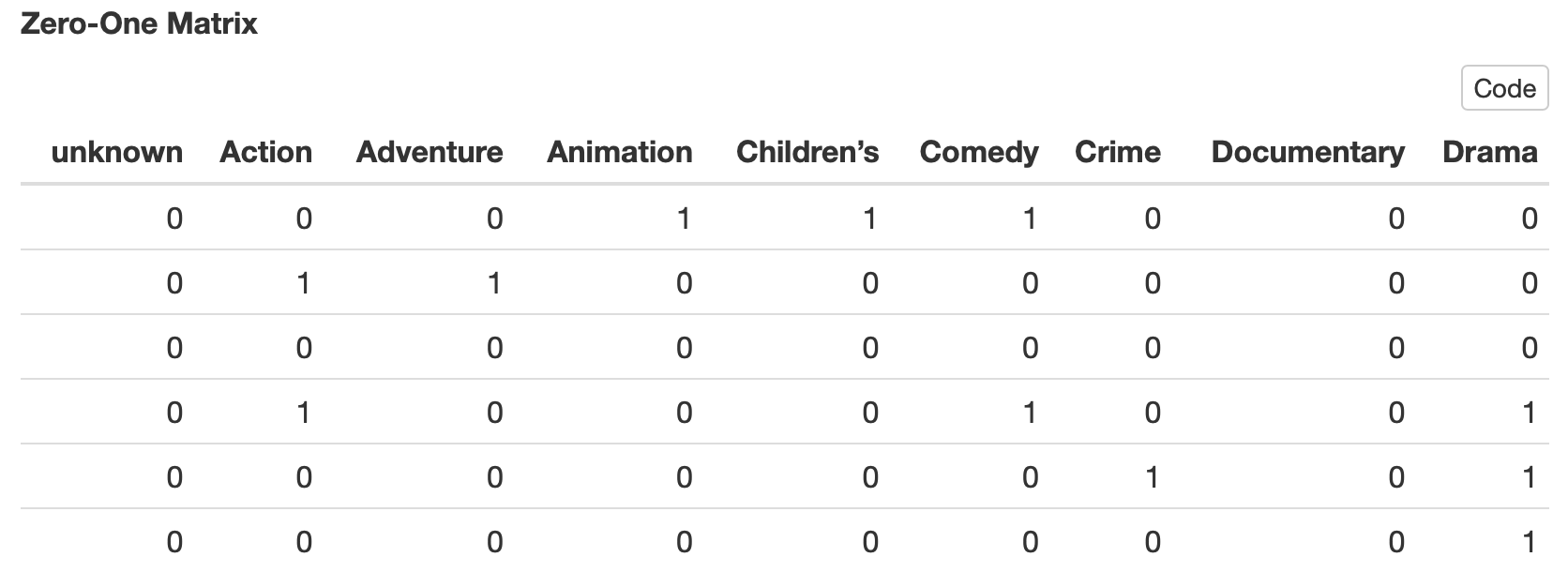
unknown ~ Western : 這裡一共有 19 個電影類別,均為 0 1 的類別變數,用來表示這部電影是否屬於該類別。
-
-
使用者對電影的評分:
-
user_id
-
movie_id
-
rating
-
tinestamp : 使用者對電影的評分時間
-
我們的最終目標是利用這筆資料的各個部分進行電影推薦系統的建模。
Exploratory Data Analysis, EDA #
Movies and User Data #
由於在使用者的數據上我們並沒有太多的發現,這是關於使用者圖表的連結 ,我們這裡的分析會以電影資料為主。
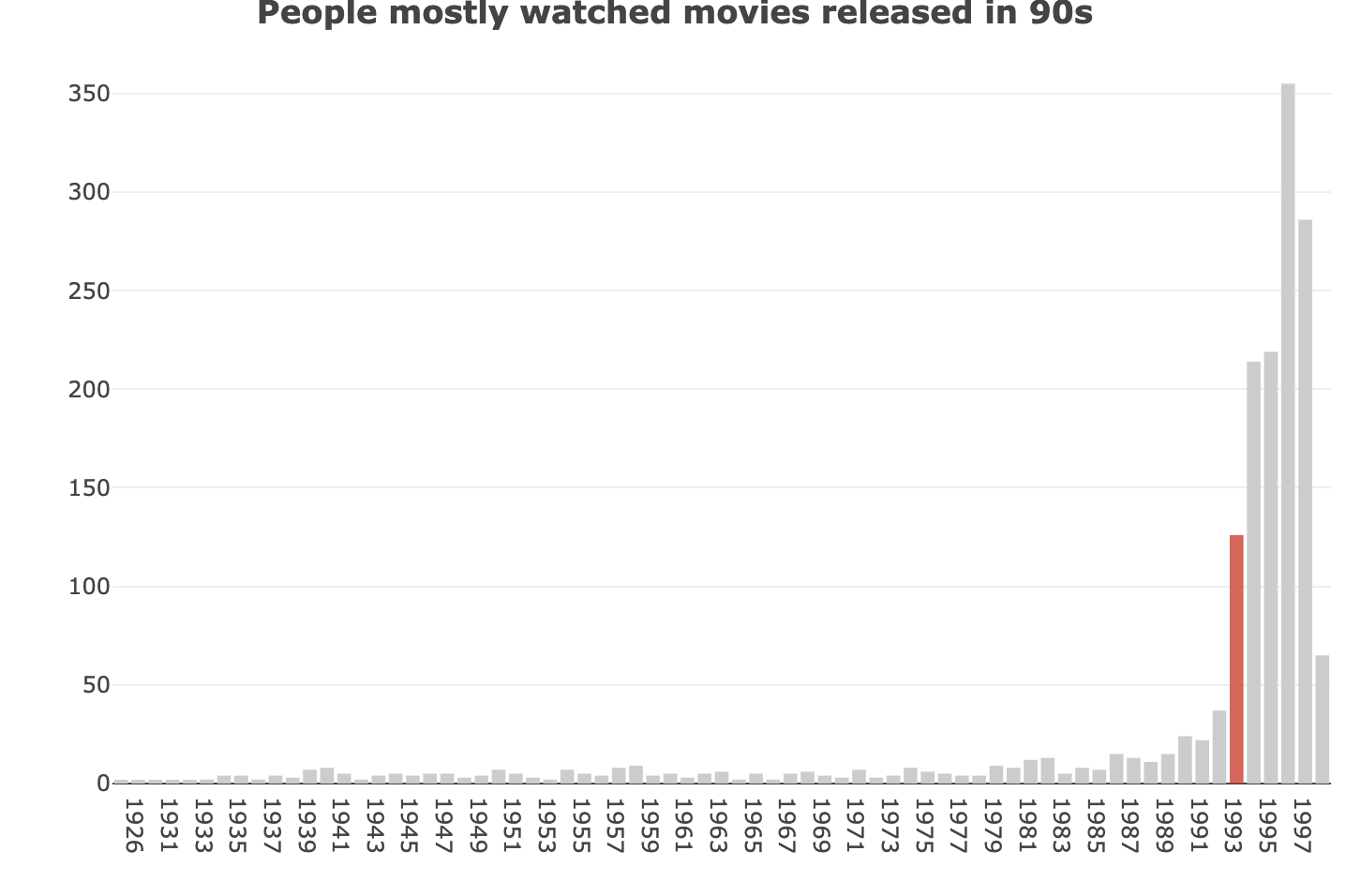
首先我們對電影的上市日期做了初步的分析,透過文字處理將資料切割成年份及日期後,我們從中發現在數據中,電影的發布年份在 1993 年之後呈現爆發式增長,經查證後發現在當年大該發生了這些事件:
-
《侏羅紀公園》的電腦生成圖像 (CGI):這部電影由史蒂芬·斯皮爾伯格執導,標誌著 CGI 技術在電影中的重大飛躍。《侏羅紀公園》使用了創新的電腦生成技術來創造真實的恐龍,這在當時是前所未有的。這不僅推動了視覺特效的極限,也改變了未來電影製作的方式。
-
數字音效和 Dolby SR-D 音效系統:1993 年也見證了音效技術的進步。Dolby SR-D(現在稱為Dolby Digital)是首次在商業電影院提供的數字音效系統,首次應用在《侏羅紀公園》中,提供更清晰、更動態的聲音體驗。
-
柯達的 Cineon 數位影像系統:該系統於 1993 年推向商業市場,對電影行業的數字後期製作領域產生了重要的影響。Cineon 系統是一種先進的數位影像處理系統,它允許用戶對攝影底片進行高質量的掃描、處理、和輸出,從而實現數字化的非線性編輯和色彩校正。這一系統的推出標誌著從傳統的底片處理向數位工作流程的重要轉變。
我們猜測是由於電影製作成本與技術門檻的下降及侏羅紀公園上映後大眾對電影燃起了興趣,進而使電影產業如雨後春筍般產出許多運用新技術的作品。
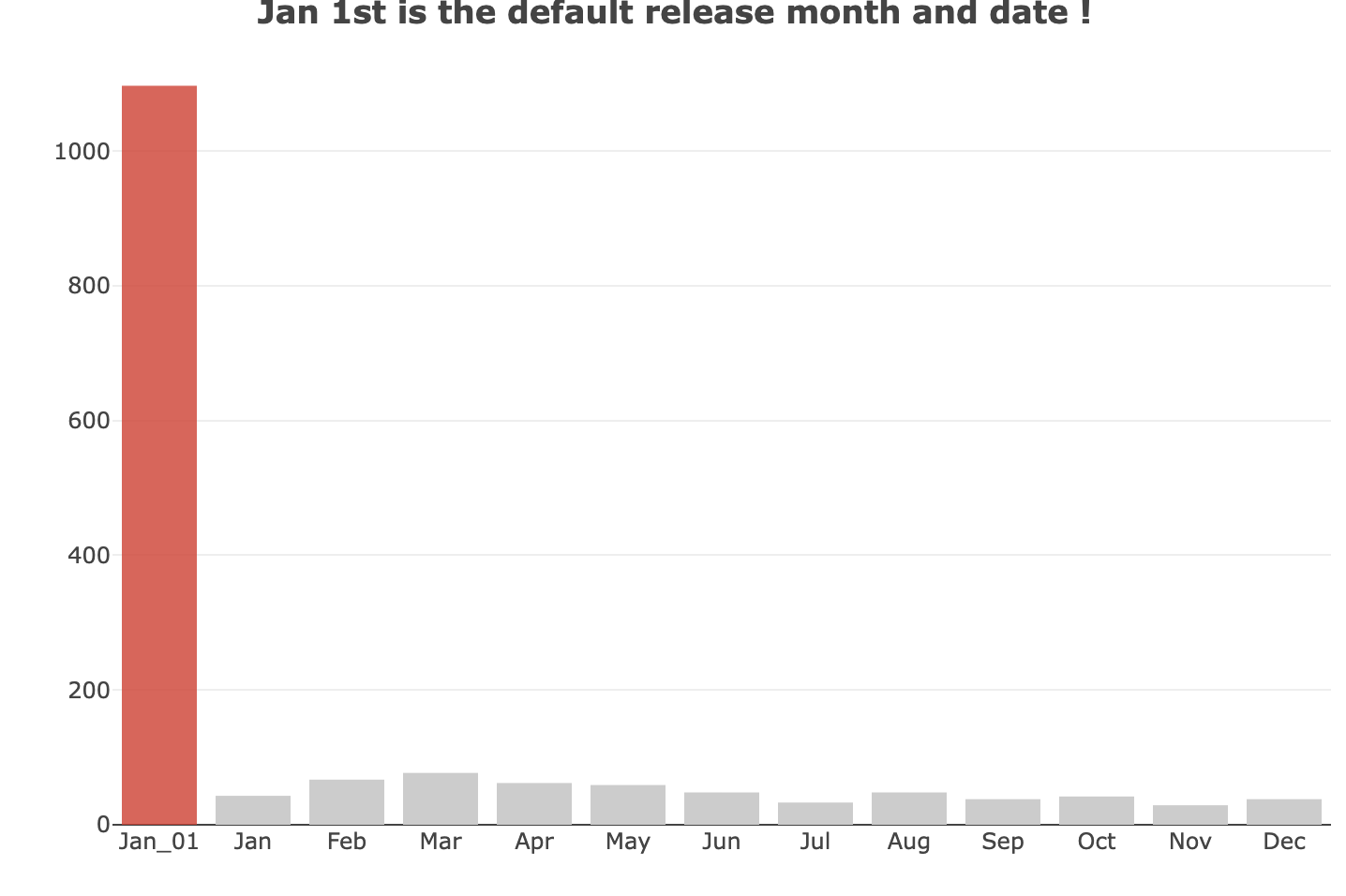
但是當我們進一步剖析資料後發現,電影的上映日期上具有很大的問題,竟然有超過六成的電影是在一月一日上映的,這顯然不合理,我們因此並沒有對日期內的資訊做進一步的挖掘。
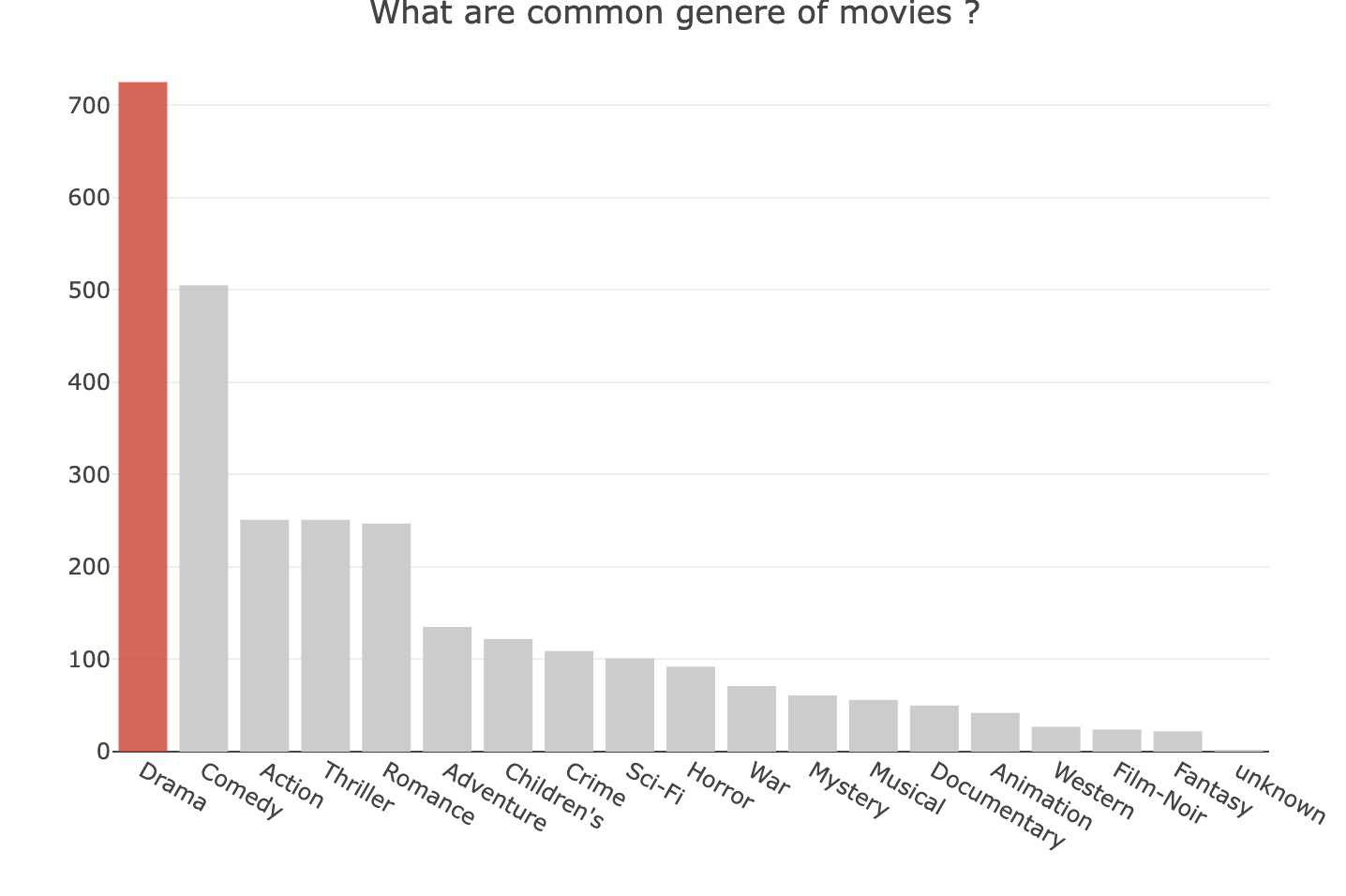
接著我們先關注到的是電影的類別,我們好奇這個離散且稀疏的矩陣中含有哪些隱藏的資訊,讓我們先來關注每個類別分別有多少電影。我們可以從圖中看出劇集、喜劇、動作、驚悚與浪漫依序為最多的前五類。
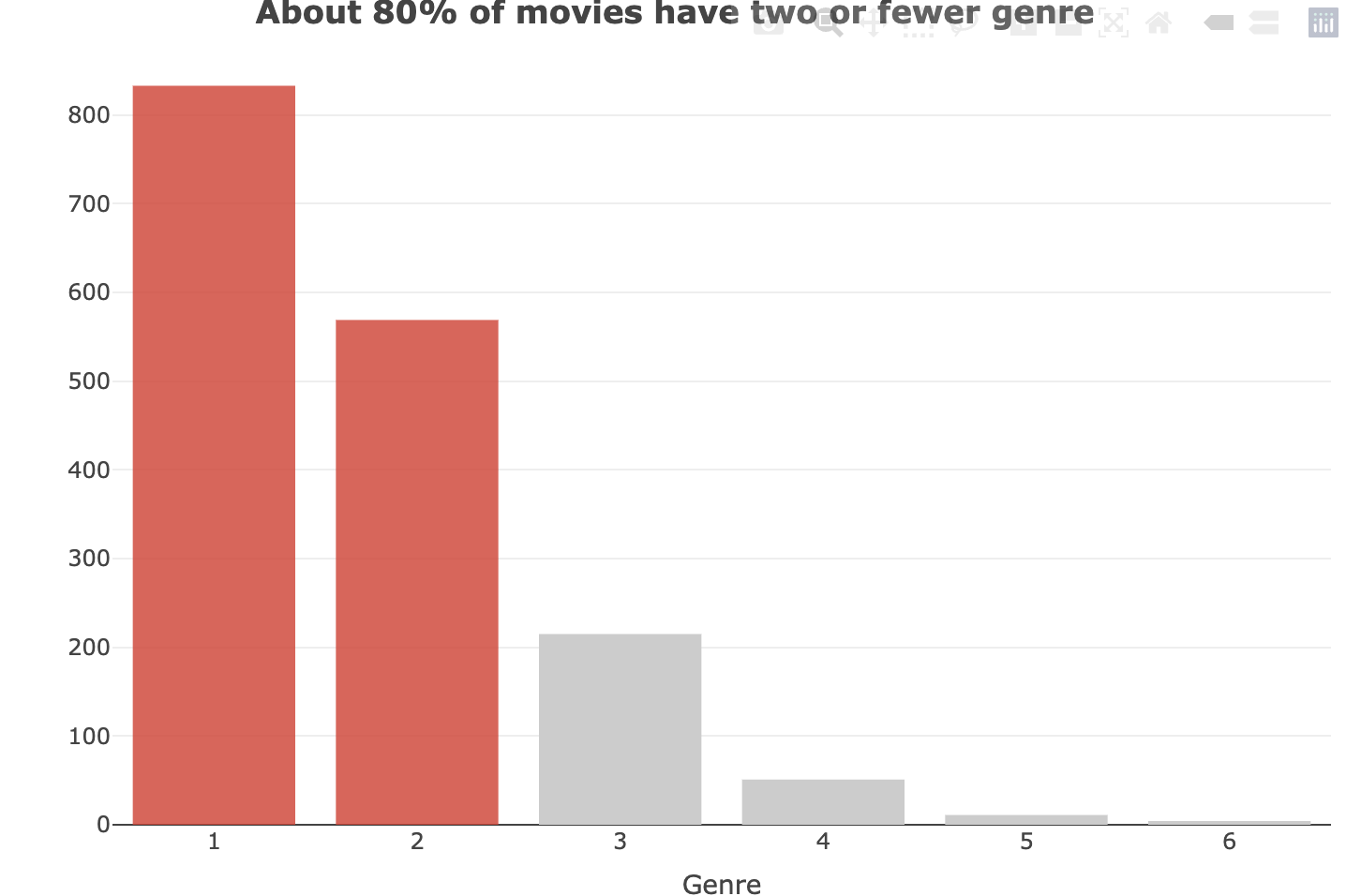
由於每個電影的類別不只擁有一類的緣故,因此我們決定觀察一下每部電影它們類別的數量分佈來做進一步的了解,而我們從中發現約有百分之八十的資料具有一至兩個類別,而擁有三個以上類別的資料是十分稀少的,由於想要視覺化它必須先進一步處理,因此我們先將剩下的發現透過 Jaccard 與 PCA 的方式做進一步解析。
Jaccard #
這裡我們簡單介紹一下 Jaccard 這個方法,它是用於計算兩個集合 $U$ 和 $V$ 的相似度,公式如下所示。
\( J(U,V) = \frac{|U \cap V|}{|U \cup V|} \)
為了能更淺顯易懂的解釋它,讓我來舉一個簡單的例子:
今天有 \( U \) 和 \( V \) 兩名顧客進入賣場買東西,我們想知道他們兩人所消費的物品相似度有多高。接著我們假設 \( U \) 買了礦泉水和洋芋片,而 \( V \) 買了汽水及洋芋片,那麼他們兩人的交集 \( U \cap V \) 只有洋芋片一項物品,而他們的聯集 \( U \cup V \) 有礦泉水、汽水和洋芋片,那麼他們兩人的 Jaccard 相似度便是 \( \frac{1}{3} \)。同理可知若是兩個人買了完全一樣的物品,那麼他們的相似度便會是 1,反之,若兩人沒有購買任何相同的物品,那麼他們的相似度便會是 0。
接著我們再來講解一下與相似度相同的一個概念,它便是 Jaccard 距離。
\( d_J(U,V) = 1 - \frac{|U \cap V|}{|U \cup V|} \)
Jaccard 距離便是將原本相似度的概念翻轉過來,若是兩個人買了完全一樣的物品,那麼他們的距離便會是 0,反之,若兩人沒有購買任何相同的物品,那麼他們的距離便會是 1。
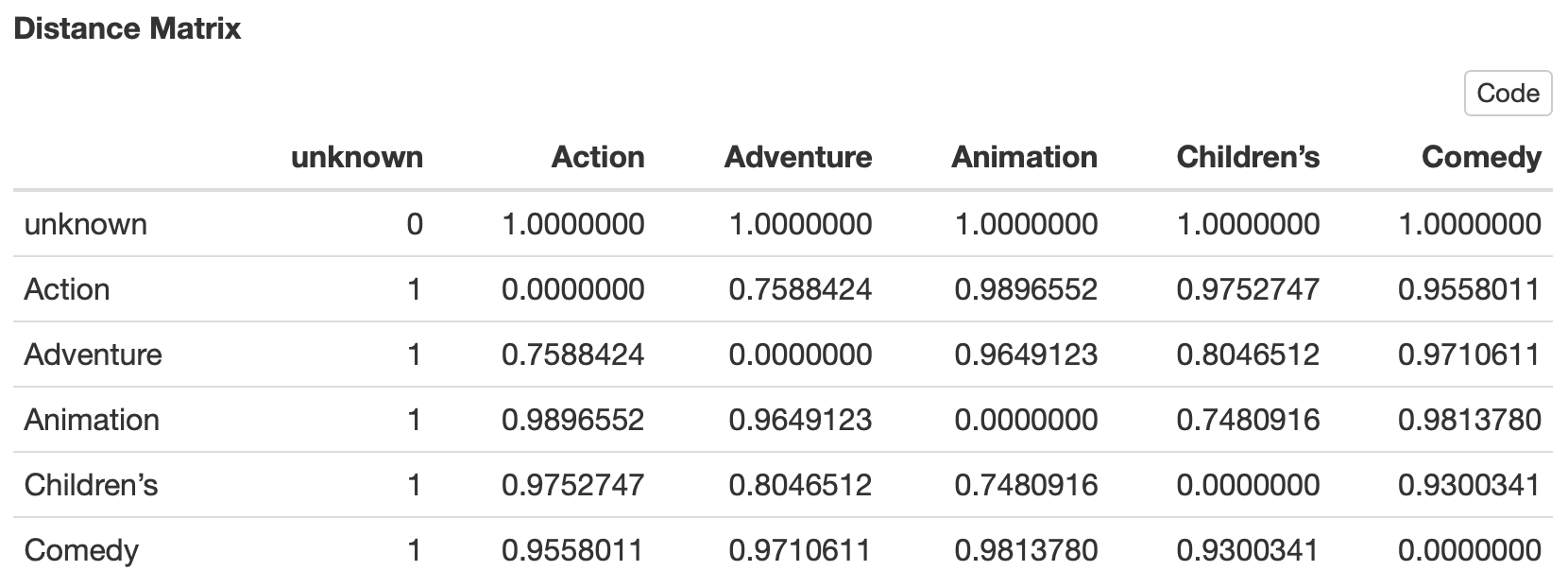
下面讓我們來看看原本離散的矩陣透過 Jaccard 轉置後所得到的,下面分別是原始的稀疏矩陣及以電影類別分類轉置後的距離矩陣,透過 Jaccard 算法可以讓我們在後續進行數據將維及視覺化的效果有更近一步的提升。
至於主成分分析(PCA)和 t 分佈隨機鄰近嵌入(t-SNE)兩個算法,由於這裡的篇幅有限就不詳細說明,後續我會新增關於這兩個算法的詳細解說。
Dimension Reduction #
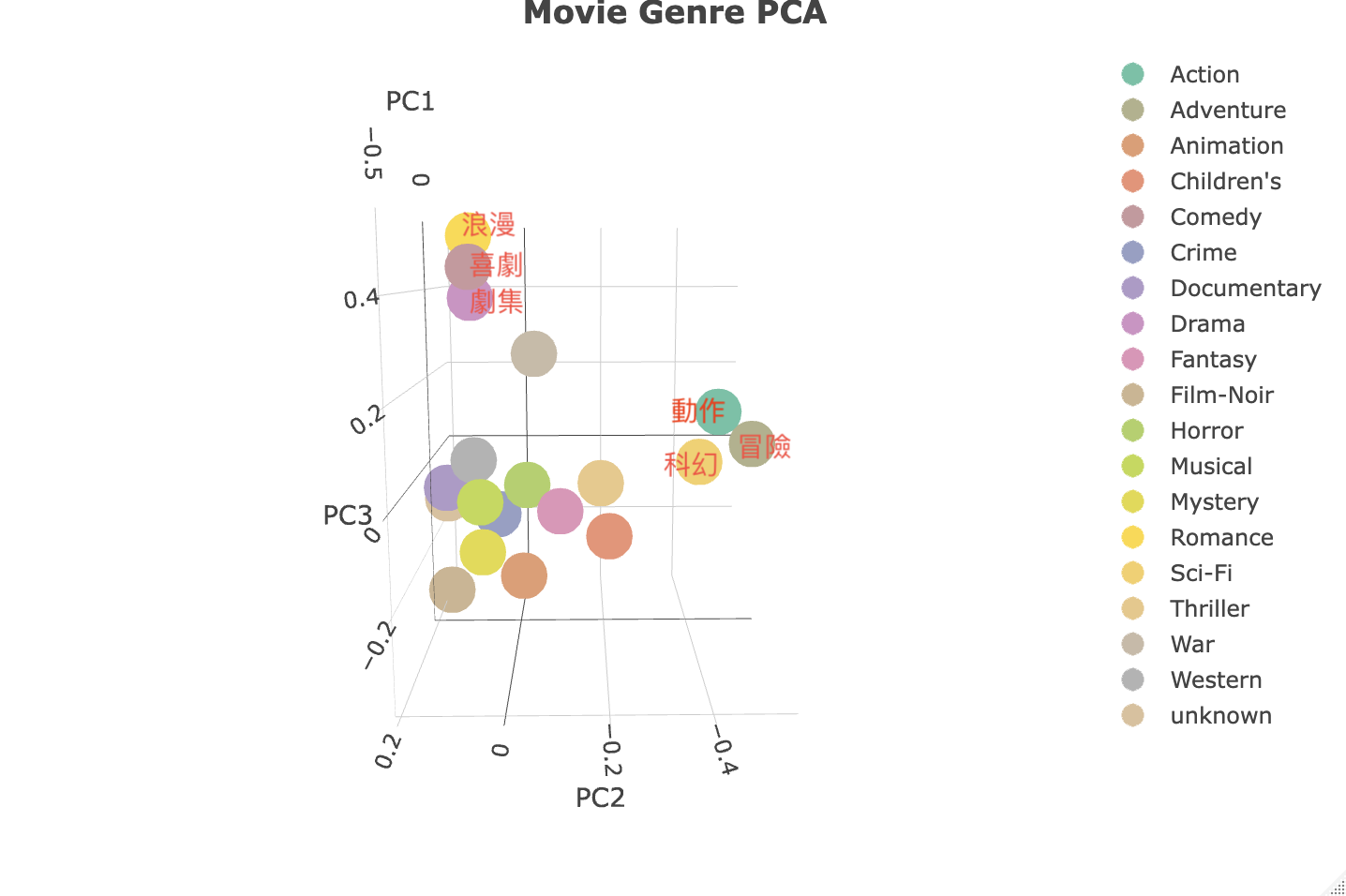
接著讓我們來用圖片來展示將電影類別資料視覺化後的成果,又因為在三維空間能更好的說明它,因此我也製作了可互動式的網頁連結 ,裡面分別有原始的程式檔及可以進行縮放及旋轉的圖片,以便於搭配文字說明可以更好的理解內容。
首先我們先來看到第一張圖中左上角的三個點,它們分別是浪漫、喜劇及劇集,這三種類型的電影相較於其他類型較為互相接近,它們的距離可以被我們解釋為較為相似的主題,而第一張圖中間靠右的三個點他們分別是動作、冒險及科幻,
而下方的群體便需要我們轉動角度才能更好的觀察它們,我們可以在第二張圖下方看到的三個點分別是音樂、卡通及兒童。
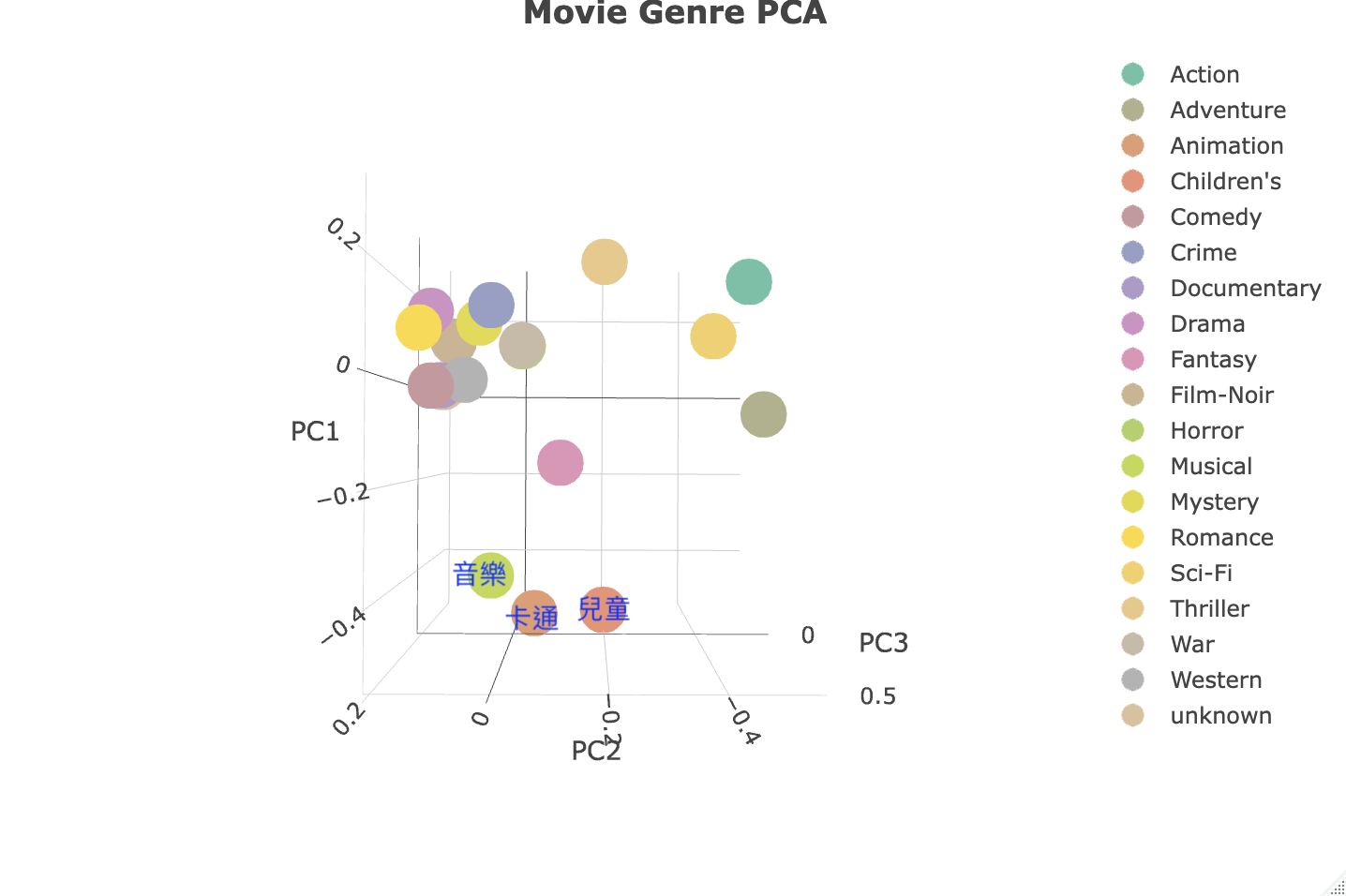
最後我們可以將剩下的點大致上看成三個區塊,他們分別是驚悚與恐怖片、西部與紀錄片、神秘黑暗的犯罪電影。
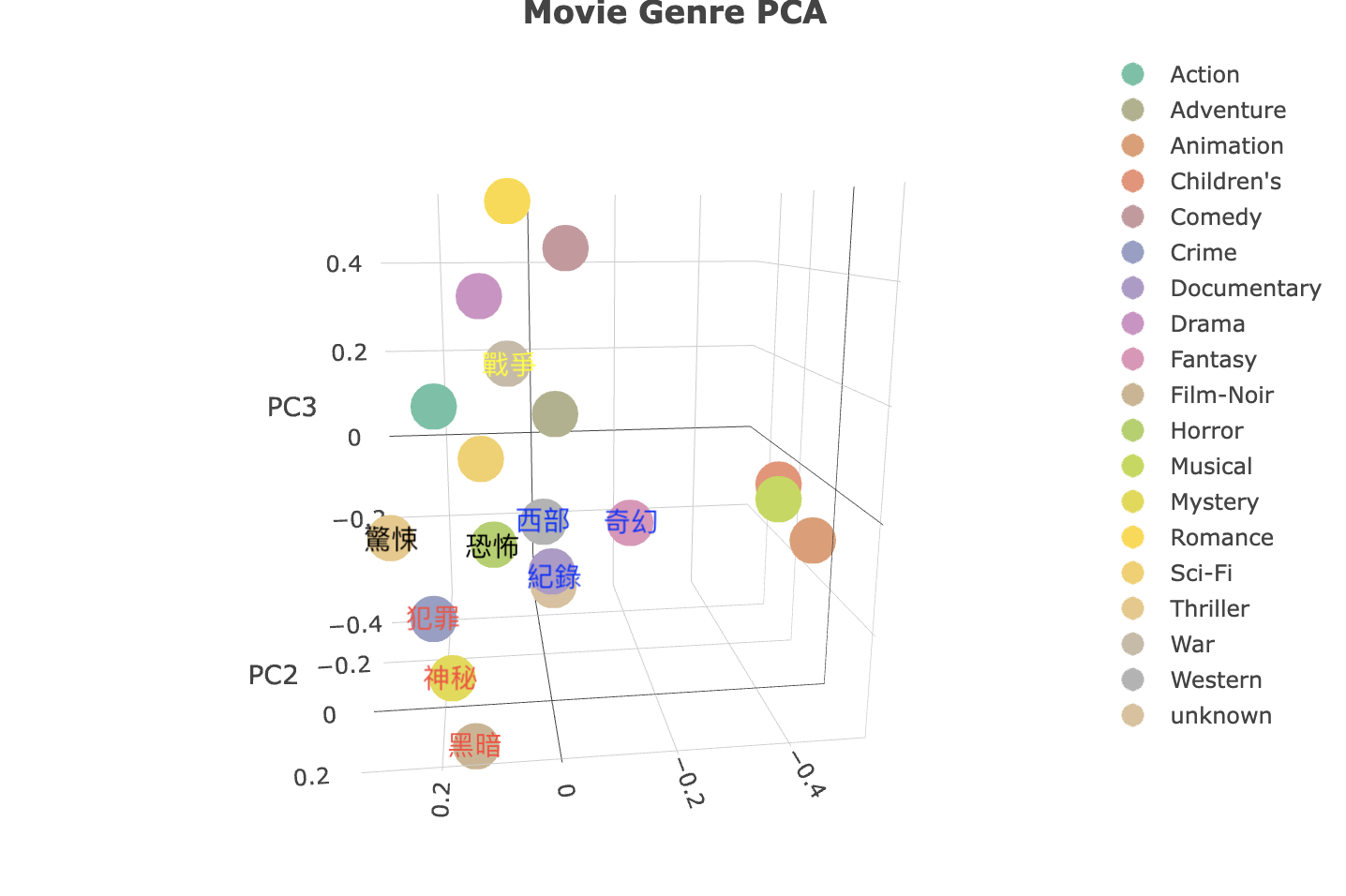
從上面的圖我們可以很好的釐清電影類別之間的關係,同時他們的距離關係也可以被合理的解釋。但因為這次報告時間的緣故,我們並沒有將這個視覺化成果的資訊加入後續的模型中,但這對我而言是一個對數據處理新的嘗試,同時也在分類上做出了不錯的成效。
Recommender System #
在開始構築推薦系統前,我們先對資料進行了刪減,原因是我們認為,要將該條評分用於構建推薦系統需要滿足以下兩個條件:
-
該名評分的使用者必須要曾評分過足夠多的電影,那麼他的評分相對只評過一兩部電影的人而言,分數會較為具有參考性,因為它的評分是建立在一定的樣本基數上的。
-
電影同樣也須收到足夠的評分才會被用於訓練模型。
經過對不同組參數的設定比較,我們最終決定採用曾評分過 50 則評分的使用者與曾收到 50 則評分的電影作為訓練資料。而經過我們的篩選,評分剩下 73544條,參與的使用者與電影也從 943 位使用者對 1682 部電影的評價變成 568 位使用者對 603 部電影的評價。
接著我們定義模型訓練時,用戶必須給出從1-5分的範圍中給出4分才算是對於這部電影的正面評價,同時我們採用K折交叉驗證(K-Fold Cross Validation)來確保模型不會過度擬合,在這裡的模型建構中,我們將K設定為5。接下拉讓我們來簡單的介紹一下這次分析有使用到的方法。同時原始程式與推薦出的結果我將它放在下方不同推薦系統標題中的連結。
User-Based Collaborative Filtering #
首先是用戶為基礎的協同過濾,又簡稱為(User-Based CF)是一種基於用戶相似度的推薦方法。該方法假設如果兩個用戶對相似的物品評分相似,那麼他們在其他物品上的評分也可能相似。目標為通過找出與目標用戶評分行為相似的用戶,向目標用戶推薦這些相似用戶喜歡的物品。
他的優點為容易理解和實現,並且當有大量用戶評分數據時,推薦效果較好。但他也有隨著用戶數量增長,計算相似度的開銷將會變得很大導致效率低下的問題,同時也會面臨冷啟動問題,也就是當有新物品進入推薦系統時,由於資料量不足,系統無法第一時間抓取足夠的數據以在空間中定義相似度的情況。
Item-Based Collaborative Filtering #
接著是以物品為基礎的協同過濾(Item-Based CF),是基於物品相似度的推薦方法。該方法假設如果一個用戶喜歡某個物品,他可能會喜歡與之相似的物品。因此我們通過找出與目標物品相似的物品,進而可以向用戶推薦這些相似物品。
優點為當物品數量相對穩定時,計算效率較高。並且在用戶的冷啟動問題相較而言較容易處理。不過當物品數量巨大時,計算相似度的開銷仍然很大,同時依然面臨在推薦新物品時的冷啟動問題。
FunkSVD #
最後則是 FunkSVD,它是一種基於矩陣分解的推薦算法,利用奇異值分解(Singular Value Decomposition,SVD)來分解用戶與物品的評分矩陣,試圖將用戶和物品映射到一個共同的潛在特徵空間,並基於這些潛在由線性組合生成的特徵進行推薦。
它的優點為能夠捕捉到用戶和物品的隱含特徵,並且對於稀疏矩陣表現優秀又能夠處理大規模數據。但是訓練過程較慢,尤其是當數據量很大時更是如此。
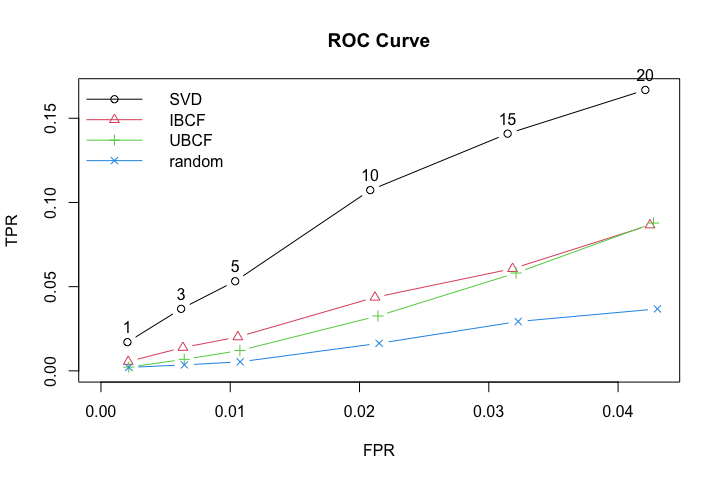
我們可以在下方的 ROC曲線 看到不同推薦系統在推薦不同數量電影時的表現,可以看出FunkSVD作出的推薦相較其他模型更為精準,但其他兩個模型也相較隨機推薦的效果來的佳,作為構建成本較低的方案也不失為一個選擇。
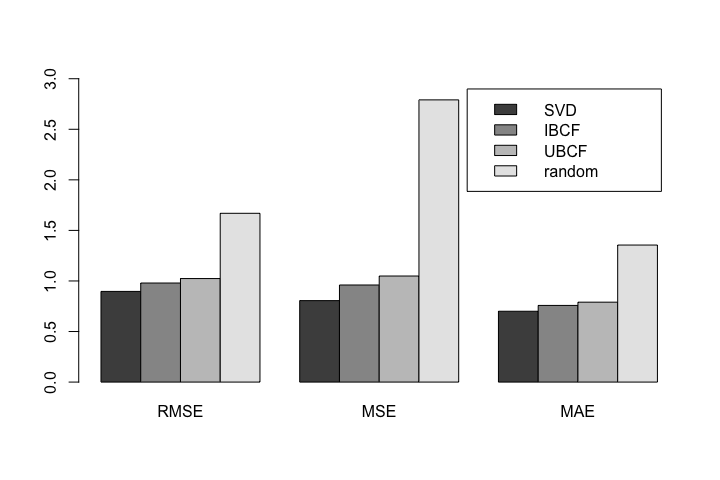
最後為了能更直觀的看出各個推薦系統之間的效果,我們也繪製了比較模型與真實評分誤差的圖表以供參考。
Conclusion #
我們在這次的資料分析中嘗試了不同類型目標的模型建構,透過我們建構的模型可以看出不同方法在這次的電影資料中具有不同的效果,而這些方法所適合的資料類型也不盡相同,但他們都在這次的建模中發揮不錯的成效。同時我們也將電影的類別透過 PCA 求得特徵向量後在視覺化做呈現,這讓我們更加釐清電影之間的關係,也為後續 FunkSVD 的模型建構做先一步的數據探索。
後續工作與感想
關於這筆資料我們或許可以將其做成 ShinyApps 將其連結至網路做更好的結果展示,同時也能嘗試將前面所提取出的特徵進一步優化模型的效果。而最後我對這次報告的經驗讓我於推薦系統領域獲益良多,讓我得以繼續在資料分析領域尋找許多不同的問題去細細品味。